Шифрование и хеширование тест ответы
HackWare.ru
Этичный хакинг и тестирование на проникновение, информационная безопасность
Хеши: определение типа, подсчёт контрольных сумм, нестандартные и итерированные хеши
Что такое хеши и как они используются
Хеш-сумма (хеш, хеш-код) — результат обработки неких данных хеш-функцией (хеширования).
Хеширование, реже хэширование (англ. hashing) — преобразование массива входных данных произвольной длины в (выходную) битовую строку фиксированной длины, выполняемое определённым алгоритмом. Функция, реализующая алгоритм и выполняющая преобразование, называется «хеш-функцией» или «функцией свёртки». Исходные данные называются входным массивом, «ключом» или «сообщением». Результат преобразования (выходные данные) называется «хешем», «хеш-кодом», «хеш-суммой», «сводкой сообщения».
Это свойство хеш-функций позволяет применять их в следующих случаях:
- при построении ассоциативных массивов;
- при поиске дубликатов в сериях наборов данных;
- при построении уникальных идентификаторов для наборов данных;
- при вычислении контрольных сумм от данных (сигнала) для последующего обнаружения в них ошибок (возникших случайно или внесённых намеренно), возникающих при хранении и/или передаче данных;
- при сохранении паролей в системах защиты в виде хеш-кода (для восстановления пароля по хеш-коду требуется функция, являющаяся обратной по отношению к использованной хеш-функции);
- при выработке электронной подписи (на практике часто подписывается не само сообщение, а его «хеш-образ»);
- и др.
Одним из применений хешов является хранение паролей. Идея в следующем: когда вы придумываете пароль (для веб-сайта или операционной системы) сохраняется не сам пароль, а его хеш (результат обработки пароля хеш-функцией). Этим достигается то, что если система хранения паролей будет скомпрометирована (будет взломан веб-сайт и злоумышленник получит доступ к базе данных паролей), то он не сможет узнать пароли пользователей, поскольку они сохранены в виде хешей. Т.е. даже взломав базу данных паролей он не сможет зайти на сайт под учётными данными пользователей. Когда нужно проверить пароль пользователя, то для введённого значения также рассчитывается хеш и система сравнивает два хеша, а не сами пароли.
По этой причине пентестер может столкнуться с необходимостью работы с хешами. Одной из типичных задач является взлом хеша для получения пароля (ещё говорят «пароля в виде простого текста» — поскольку пароль в виде хеша у нас и так уже есть). Фактически, взлом заключается в подборе такой строки (пароля), которая будет при хешировании давать одинаковое значение со взламываемым хешем.
Для взлома хешей используется, в частности, Hashcat. Независимо от выбранного инструмента, необходимо знать, хеш какого типа перед нами.
Как определить тип хеша
Существует большое количество хешей. Некоторые из них являются универсальными и применяются различными приложениями, например, MD5, SHA1, CRC8 и другие. Некоторые хеши применяются только в определённых приложениях (MySQL, vBulletin) и протоколами.
Кроме популярных хешей, разработчики могут использовать различные сочетания универсальных хешей (например, посчитать хеш с помощью MD5, а затем для полученной строки получить хеш SHA1), либо итерированные (с повторением) хеши (например, для пароля рассчитывается MD5 хеш, затем для полученной строки вновь рассчитывается MD5 хеш, затем для полученной строки вновь считается MD5 – и так тысячу раз).
Применительно к взлому, иногда хешем называют сформированную определённым образом строку или файл, которые не применяются целевым приложением, но которые были рассчитаны исходя из исходных данных так, что позволяют взломать пароль целевого файла или протокола.
Пример такой строки для WinZip: $zip2$*0*3*0*b5d2b7bf57ad5e86a55c400509c672bd*d218*0**ca3d736d03a34165cfa9*$/zip2$
Пример строки для взлома пароля файла PDF 1.7 Level 8 (Acrobat 10 — 11): $pdf$5*6*256*-4*1*16*381692e488413f5502fa7314a78c25db*48*e5bf81a2a23c88f3dccb44bc7da68bb5606b653b733bcf9adaa5eb2c8ccf53abba66539044eb1957eda68469b1d0b9b5*48*b222df06deb308bf919d13447e688775fdcab972faed2c866dc023a126cb4cd4bbffab3683ecde243cf8d88967184680
Обычно пентестеру известен источник хеша и он знает его тип. Но бывают исключения. В этой ситуации необходимо «угадать» какой хеш перед нами.
Это можно сделать сравнивая исходный хеш с образцами. Либо исходя из количества символов и используемого набора символов.
Также можно использовать инструменты, которые значительно ускоряют этот процесс. Программами для определения типа хеша являются hashID и HashTag.
hashID
Эта программа по умолчанию уже установлена в Kali Linux. Она идентифицирует различные типы хешей, используемых для шифрования данных, в первую очередь, паролей.
hashID – это инструмент, написанный на Python 3, который поддерживает идентификацию более 220 уникальных типов хешей используя регулярные выражения.
Использование программы очень простое:
Пара важных замечаний:
- хеш всегда лучше указывать в одинарных кавычках (а не без кавычек и не в двойных)
- имеется опция -m, при использовании которой выводится информация о режиме Hashcat
Хеш режимы Hashcat – это условное обозначение типа хеша, которое необходимо указать с опцией -m, —hash-type.
Информацию о других опциях hashID вы найдёте здесь: https://kali.tools/?p=2772
К примеру, мне необходимо идентифицировать хеш $S$C33783772bRXEx1aCsvY.dqgaaSu76XmVlKrW9Qu8IQlvxHlmzLf:

Как можно увидеть по скриншоту, это Drupal > v7.x в Hashcat для взлома данного хеша необходимо указать режим 7900.
Идентифицируем хеш $1$VnG/6ABB$t6w9bQFxvI9tf0sFJf2TR.:
Получаем сразу несколько вариантов:
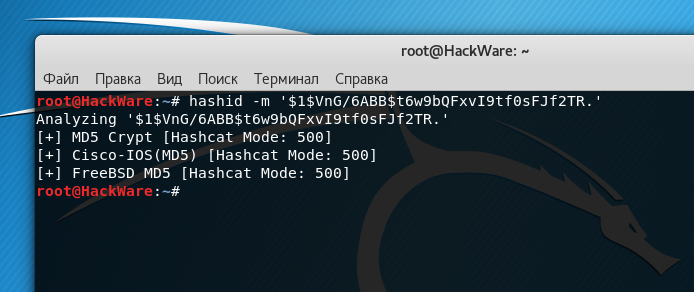
MD5cryp – это алгоритм, который вызывает тысячу раз стандартный MD5, для усложнения процесса.
Для справки: MD5 использовался для хеширования паролей. В системе UNIX каждый пользователь имеет свой пароль и его знает только пользователь. Для защиты паролей используется хеширование. Предполагалось, что получить настоящий пароль можно только полным перебором. При появлении UNIX единственным способом хеширования был DES (Data Encryption Standard), но им могли пользоваться только жители США, потому что исходные коды DES нельзя было вывозить из страны. Во FreeBSD решили эту проблему. Пользователи США могли использовать библиотеку DES, а остальные пользователи имеют метод, разрешённый для экспорта. Поэтому в FreeBSD стали использовать MD5 по умолчанию. Некоторые Linux-системы также используют MD5 для хранения паролей.
Ещё один хеш $6$q8C1F6tv$zTP/eEVixqyQBEfsSbTidUJfnaE2ojNIpTwTHava/UhFORv3V4ehyTOGdQEoFo1dEVG6UcXwhG.UHvyQyERz01:

Программа говорит, что это SHA-512 Crypt – т.е. SHA512 (Unix).
HashTag
HashTag – это инструмент на python, который разбирает и идентифицирует различные хеши паролей на основе их типа. HashTag поддерживает определение более 250 типов хешей и сопоставляет их с более чем 110 режимами hashcat. HashTag способен идентифицировать единичный хеш, разобрать единичный файл и определить хеши внутри него или обойти директорию и все поддиректории в поисках потенциальных файлов хешей и идентифицировать все найденные хеши.
Т.е. это аналогичная предыдущей программа.
По умолчанию в Kali Linux она отсутствует, поэтому требуется её скачать:
Хеш для HashTag также нужно помещать в одинарные кавычки. Хеш нужно писать после опции -sh. Зато сразу, без дополнительных опций выводятся режимы. Информацию о других опциях HashTag вы найдёте здесь: https://kali.tools/?p=2777
Идентифицируем те же самые хеши:



Как видим, результаты аналогичны.
Примеры хешей
Большое количество классических хешей, а также хешей, специально составленных для взлома пароля и хеш-файлов вы найдёте здесь.
На той странице вы можете:
- попытаться идентифицировать свой хеш по образцам
- найти ошибку в составленном хеше для взлома пароля, сравнив его с правильным форматом
- проверить работу программ по идентификации хеша
Программы hashID и HashTag не всегда правильно идентифицируют хеш (по крайней мере, в явных ошибках замечена hashID).
К примеру, меня интересует хеш c73d08de890479518ed60cf670d17faa26a4a71f995c1dcc978165399401a6c4:53743528:
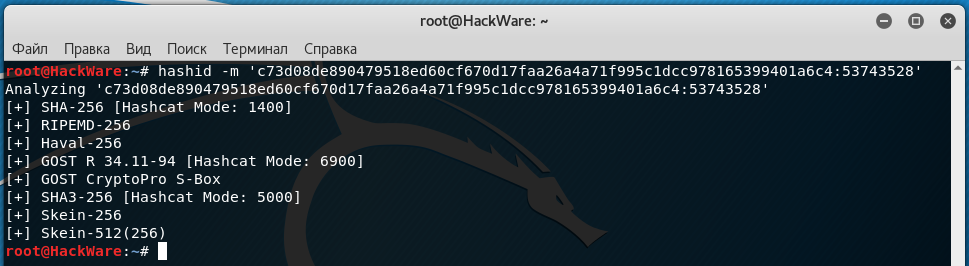
Это явно ошибочный результат, поскольку соль после двоеточия будто бы была отпрошена при идентификации хеша.
Получаем более правильный результат:
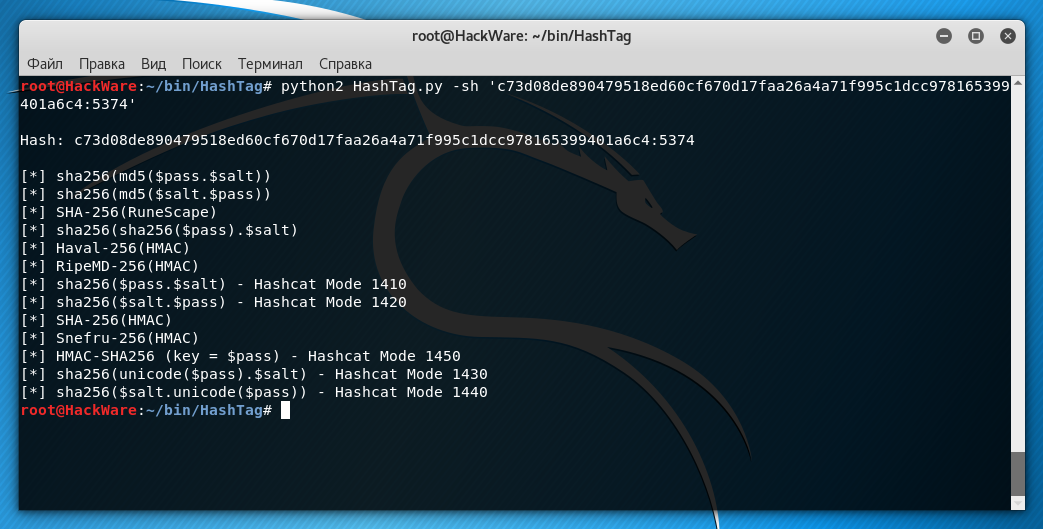
В действительности это sha256($pass.$salt).
Как рассчитать хеш (контрольную сумму)
В Linux имеются программы для расчёта и сверки популярных хешей:
- b2sum – вычисляет и проверяет криптографическую хеш-функцию BLAKE2 (512-бит)
- cksum – печатает контрольную сумму CRC и количество байт
- md5sum – печатает или проверяет контрольную сумму MD5 (128-бит)
- sha1sum – печатает или проверяет контрольную сумму SHA1 (160-бит)
- sha224sum – печатает или проверяет контрольную сумму SHA224 (224- бит)
- sha256sum – печатает или проверяет контрольную сумму SHA256 (256- бит)
- sha384sum – печатает или проверяет контрольную сумму SHA384 (384- бит)
- sha512sum – печатает или проверяет контрольную сумму SHA512 (512- бит)
Информация о SHA-2 (безопасный алгоритм хеширования, версия 2) – семействе криптографических алгоритмов (SHA-224, SHA-256, SHA-384, SHA-512, SHA-512/256 и SHA-512/224.): https://ru.wikipedia.org/wiki/SHA-2
Все эти программы установлены по умолчанию в большинстве дистрибутивов Linux, они позволяют рассчитать хеши для файлов или для строк.
Применение всех этих программ похожее – нужно указать имя файла, либо передать по стандартному вводу строку.
Если для расчёта хеша строки вы используете echo, то крайне важно указывать опцию -n, которая предотвращает добавление символа новой строки – иначе каждый хеш для строки будет неверным!
Пример подсчёта хеша SHA1 для строки test:
Ещё один способ передачи строки без добавления конечного символа newline
Как можно заметить, после хеша следует пробел и имя файла (в случае стандартного ввода – указывается тире), чтобы показать только хеш, можно использовать к команде добавить | awk '
Этот же результат можно получить следующей конструкцией:
Программы для вычисления различных хешей
Кроме перечисленных встроенных в Linux утилит, имеются другие программы, способные подсчитывать контрольные суммы. Часто они поддерживают сразу несколько алгоритмов хеширования, могут иметь дополнительные опции ввода и вывода (поддерживают различные форматы и кодировки), некоторые из них подготовлены для выполнения аудита файловой системы (выявления несанкционированных изменений в файлах).
Список некоторых популярных программ для вычисления хешей:
- hashrat
- hashdeep
- Hasher
- omnihash
Думаю, используя русскоязычную справку с примерами использования, вы без труда сможете разобраться в этих программах самостоятельно.
Последовательное хеширование с использованием трубы (|)
К примеру, нам нужно рассчитать sha256 хеш для строки 'HackWare'; а затем для полученной строки (хеша), рассчитать хеш md5. Задача кажется очень тривиальной:
Но это неправильный вариант. Поскольку результатом выполнения в любом случае является непонятная строка из случайных символов, трудно не только обнаружить ошибку, но даже понять, что она есть. А ошибок здесь сразу несколько! И каждая из них ведёт к получению абсолютно неправильных данных.
Даже очень бывалые пользователи командной строки Linux не сразу поймут в чём проблема, а обнаружив первую проблему не сразу поймут, что есть ещё одна.
Очень важно помнить, что в строке вместе с хешем всегда выводится имя файла, поэтому выполняя довольно очевидную команду вроде следующей:
мы получим совсем не тот результат, который ожидаем. Мы предполагаем посчитать sha256 хеш строки 'HackWare', а затем для полученной строки (хеша) рассчитать новый хеш md5. На самом деле, md5sum рассчитывает хеш строки, к которой прибавлено « —». Т.е. получается совершенно другой результат.
Выше уже рассмотрено, как из вывода удалять « —», кажется, теперь всё должно быть в порядке:
Давайте разобьём это действие на отдельные команды:
Второй этап хеширования:
Это и есть правильный ответ.
Проблема в том, что когда выводится промежуточный хеш, к нему добавляется символ новой строки, и второй хеш считается по этой полной строке, включающей невидимый символ!
Используя printf можно вывести результат без конечного символа новой строки:
Результат вновь правильный:
С printf не все дружат и проблематично использовать рассмотренную конструкцию если нужно хешировать более трёх раз, поэтому лучше использовать tr:
Вновь правильный результат:
Или даже сделаем ещё лучше – с программой awk будем использовать printf вместо print (это самый удобный и короткий вариант):
Как посчитать итерированные хеши
Итерация – это повторное применение какой-либо операции. Применительно к криптографии, итерациями называют многократное хеширование данных, которые получаются в результате хеширования. Например, для исходной строки в виде простого текста рассчитывается SHA1 хеш. Полученное значение вновь хешируется – рассчитывается SHA1 хеш и так далее много раз.
Итерация – очень эффективный метод для борьбы с радужными таблицами и с полным перебором (брут-форсом), поэтому в криптографии итерированные хеши очень популярны.
Алгоритм хеширования данных: просто о сложном
Криптографические хэш-функции распространены очень широко. Они используются для хранения паролей при аутентификации, для защиты данных в системах проверки файлов, для обнаружения вредоносного программного обеспечения, для кодирования информации в блокчейне (блок — основной примитив, обрабатываемый Биткойном и Эфириумом). В этой статье пойдет разговор об алгоритмах хеширования: что это, какие типы бывают, какими свойствами обладают.
В наши дни существует много криптографических алгоритмов. Они бывают разные и отличаются по сложности, разрядности, криптографической надежности, особенностям работы. Алгоритмы хеширования — идея не новая. Они появилась более полувека назад, причем за много лет с принципиальной точки зрения мало что изменилось. Но в результате своего развития хеширование данных приобрело много новых свойств, поэтому его применение в сфере информационных технологий стало уже повсеместным.
Что такое хеш (хэш, hash)?
Хеш или хэш — это криптографическая функция хеширования (function), которую обычно называют просто хэшем. Хеш-функция представляет собой математический алгоритм, который может преобразовать произвольный массив данных в строку фиксированной длины, состоящую из цифр и букв.
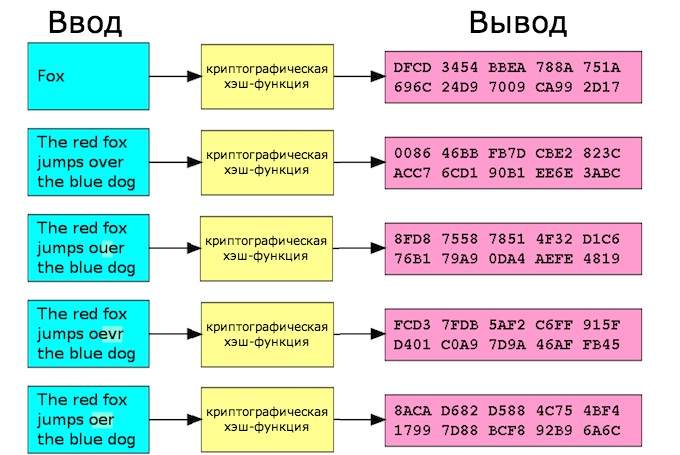
Основная идея используемых в данном случае функций — применение детерминированного алгоритма. Речь идет об алгоритмическом процессе, выдающем уникальный и предопределенный результат при получении входных данных. То есть при приеме одних и тех же входных данных будет создаваться та же самая строка фиксированной длины (использование одинакового ввода каждый раз приводит к одинаковому результату). Детерминизм — важное свойство этого алгоритма. И если во входных данных изменить хотя бы один символ, будет создан совершенно другой хэш.
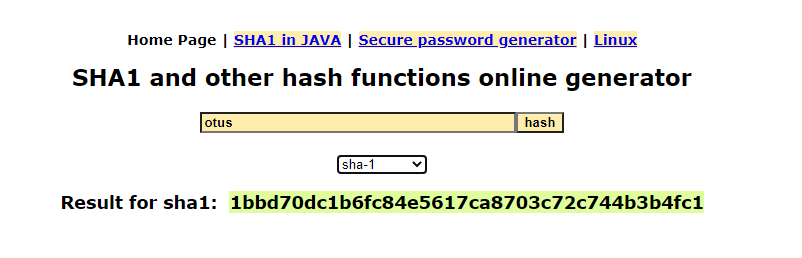
Убедиться в этом можно на любом онлайн-генераторе. Набрав слово «Otus» и воспользовавшись алгоритмом sha1 (Secure Hashing Algorithm), мы получим хеш 7576750f9d76fab50762b5987739c18d99d2aff7. При изменении любой буквы изменится и результат, причем изменится полностью. Мало того, если просто поменять регистр хотя бы одной буквы, итог тоже будет совершенно иным: если написать «otus», алгоритм хэш-функции отработает со следующим результатом: 1bbd70dc1b6fc84e5617ca8703c72c744b3b4fc1. Хотя общие моменты все же есть: строка всегда состоит из сорока символов.
В предыдущем примере речь шла о применении хэш-алгоритма для слова из 4 букв. Но с тем же успехом можно вставить слово из 1000 букв — все равно после обработки данных на выходе получится значение из 40 символов. Аналогичная ситуация будет и при обработке полного собрания сочинений Льва Толстого.
Криптостойкость функций хеширования
Говоря о криптостойкости, предполагают выполнение ряда требований. То есть хороший алгоритм обладает несколькими свойствами: — при изменении одного бита во входных данных, должно наблюдаться изменение всего хэша; — алгоритм должен быть устойчив к коллизиям; — алгоритм должен быть устойчив к восстановлению хешируемых данных, то есть должна обеспечиваться высокая сложность нахождения прообраза, а вычисление хэша не должно быть простым.
Проблемы хэшей
Одна из проблем криптографических функций хеширования — неизбежность коллизий. Раз речь идет о строке фиксированной длины, значит, существует вероятность, что для каждого ввода возможно наличие и других входов, способных привести к тому же самому хешу. В результате хакер может создать коллизию, позволяющую передать вредоносные данные под видом правильного хэша.
Цель хороших криптографических функций — максимально усложнить вероятность нахождения способов генерации входных данных, хешируемых с одинаковым значением. Как уже было сказано ранее, вычисление хэша не должно быть простым, а сам алгоритм должен быть устойчив к «атакам нахождения прообраза». Необходимо, чтобы на практике было чрезвычайно сложно (а лучше — невозможно) вычислить обратные детерминированные шаги, которые предприняты для воспроизведения созданного хешем значения.
Если S = hash (x), то, в идеале, нахождение x должно быть практически невозможным.
Алгоритм MD5 и его подверженность взлому
MD5 hash — один из первых стандартов алгоритма, который применялся в целях проверки целостности файлов (контрольных сумм). Также с его помощью хранили пароли в базах данных web-приложений. Функциональность относительно проста — алгоритм выводит для каждого ввода данных фиксированную 128-битную строку, задействуя для вычисления детерминированного результата однонаправленные тривиальные операции в нескольких раундах. Особенность — простота операций и короткая выходная длина, в результате чего MD5 является относительно легким для взлома. А еще он обладает низкой степенью защиты к атаке типа «дня рождения».
Атака дня рождения
Если поместить 23 человека в одну комнату, можно дать 50%-ную вероятность того, что у двух человек день рождения будет в один и тот же день. Если же количество людей довести до 70-ти, вероятность совпадения по дню рождения приблизится к 99,9 %. Есть и другая интерпретация: если голубям дать возможность сесть в коробки, при условии, что число коробок меньше числа голубей, окажется, что хотя бы в одной из коробок находится более одного голубя.

Вывод прост: если есть фиксированные ограничения на выход, значит, есть и фиксированная степень перестановок, на которых существует возможность обнаружить коллизию.
Когда разговор идет о сопротивлении коллизиям, то алгоритм MD5 действительно очень слаб. Настолько слаб, что даже бытовой Pentium 2,4 ГГц сможет вычислить искусственные хеш-коллизии, затратив на это чуть более нескольких секунд. Всё это в ранние годы стало причиной утечки большого количества предварительных MD5-прообразов.
SHA1, SHA2, SHA3
Secure Hashing Algorithm (SHA1) — алгоритм, созданный Агентством национальной безопасности (NSA). Он создает 160-битные выходные данные фиксированной длины. На деле SHA1 лишь улучшил MD5 и увеличил длину вывода, а также увеличил число однонаправленных операций и их сложность. Однако каких-нибудь фундаментальных улучшений не произошло, особенно когда разговор шел о противодействии более мощным вычислительным машинам. Со временем появилась альтернатива — SHA2, а потом и SHA3. Последний алгоритм уже принципиально отличается по архитектуре и является частью большой схемы алгоритмов хеширования (известен как KECCAK — «Кетч-Ак»). Несмотря на схожесть названия, SHA3 имеет другой внутренний механизм, в котором используются случайные перестановки при обработке данных — «Впитывание» и «Выжимание» (конструкция «губки»).
Что в будущем?
Вне зависимости от того, какие технологии шифрования и криптографические новинки будут использоваться в этом направлении, все сводится к решению одной из двух задач: 1) увеличению сложности внутренних операций хэширования; 2) увеличению длины hash-выхода данных с расчетом на то, что вычислительные мощности атакующих не смогут эффективно вычислять коллизию.
И, несмотря на появление в будущем квантовых компьютеров, специалисты уверены, что правильные инструменты (то же хэширование) способны выдержать испытания временем, ведь ни что не стоит на месте. Дело в том, что с увеличением вычислительных мощностей снижается математическая формализация структуры внутренних алгоритмических хэш-конструкций. А квантовые вычисления наиболее эффективны лишь в отношении к вещам, имеющим строгую математическую структуру.