ea is the windows-1251 / cp5347 encoding for к . Therefore, you need to use windows-1251 decoding, not UTF-8.
In Python 2.7, the CSV library does not support Unicode properly — See «Unicode» in https://docs.python.org/2/library/csv.html
They propose a simple work around using:
class UnicodeReader: """ A CSV reader which will iterate over lines in the CSV file "f", which is encoded in the given encoding. """ def __init__(self, f, dialect=csv.excel, encoding="utf-8", **kwds): f = UTF8Recoder(f, encoding) self.reader = csv.reader(f, dialect=dialect, **kwds) def next(self): row = self.reader.next() return [unicode(s, "utf-8") for s in row] def __iter__(self): return self This would allow you to do:
def loadCsv(filename): lines = UnicodeReader(open(filename, "rb"), delimiter=";", encoding="windows-1251" ) # if you really need lists then uncomment the next line # this will let you do call exact lines by doing `line_12 = lines[12]` # return list(lines) # this will return an "iterator", so that the file is read on each call # use this if you'll do a `for x in x` return lines If you try to print dataset , then you’ll get a representation of a list within a list, where the first list is rows, and the second list is colums. Any encoded bytes or literals will be represented with x or u . To print the values, do:
for csv_line in loadCsv("myfile.csv"): print u", ".join(csv_line) If you need to write your results to another file (fairly typical), you could do:
with io.open("my_output.txt", "w", encoding="utf-8") as my_ouput: for csv_line in loadCsv("myfile.csv"): my_output.write(u", ".join(csv_line)) This will automatically convert/encode your output to UTF-8.
Code Sample, a copy-pastable example if possible
import pandas cyrillic_filename = "./файл_1.csv" # 'c' engine fails: df = pandas.read_csv(cyrillic_filename, engine="c", encoding="cp1251") --------------------------------------------------------------------------- OSError Traceback (most recent call last) ipython-input-18-9cb08141730c> in module>() 2 3 cyrillic_filename = "./файл_1.csv" ----> 4 df = pandas.read_csv(cyrillic_filename , engine="c", encoding="cp1251") d:_devservicesprotocol_sortvenvlibsite-packagespandasioparsers.py in parser_f(filepath_or_buffer, sep, delimiter, header, names, index_col, usecols, squeeze, prefix, mangle_dupe_cols, dtype, engine, converters, true_values, false_values, skipinitialspace, skiprows, nrows, na_values, keep_default_na, na_filter, verbose, skip_blank_lines, parse_dates, infer_datetime_format, keep_date_col, date_parser, dayfirst, iterator, chunksize, compression, thousands, decimal, lineterminator, quotechar, quoting, escapechar, comment, encoding, dialect, tupleize_cols, error_bad_lines, warn_bad_lines, skipfooter, skip_footer, doublequote, delim_whitespace, as_recarray, compact_ints, use_unsigned, low_memory, buffer_lines, memory_map, float_precision) 653 skip_blank_lines=skip_blank_lines) 654 --> 655 return _read(filepath_or_buffer, kwds) 656 657 parser_f.__name__ = name d:_devservicesprotocol_sortvenvlibsite-packagespandasioparsers.py in _read(filepath_or_buffer, kwds) 403 404 # Create the parser. --> 405 parser = TextFileReader(filepath_or_buffer, **kwds) 406 407 if chunksize or iterator: d:_devservicesprotocol_sortvenvlibsite-packagespandasioparsers.py in __init__(self, f, engine, **kwds) 762 self.options['has_index_names'] = kwds['has_index_names'] 763 --> 764 self._make_engine(self.engine) 765 766 def close(self): d:_devservicesprotocol_sortvenvlibsite-packagespandasioparsers.py in _make_engine(self, engine) 983 def _make_engine(self, engine='c'): 984 if engine == 'c': --> 985 self._engine = CParserWrapper(self.f, **self.options) 986 else: 987 if engine == 'python': d:_devservicesprotocol_sortvenvlibsite-packagespandasioparsers.py in __init__(self, src, **kwds) 1603 kwds['allow_leading_cols'] = self.index_col is not False 1604 -> 1605 self._reader = parsers.TextReader(src, **kwds) 1606 1607 # XXX pandas_libsparsers.pyx in pandas._libs.parsers.TextReader.__cinit__ (pandas_libsparsers.c:4209)() pandas_libsparsers.pyx in pandas._libs.parsers.TextReader._setup_parser_source (pandas_libsparsers.c:8895)() OSError: Initializing from file failed # 'python' engine work: df = pandas.read_csv(cyrillic_filename, engine="python", encoding="cp1251") df.size >>172440 # 'c' engine works if filename can be encoded to utf-8 latin_filename = "./file_1.csv" df = pandas.read_csv(latin_filename, engine="c", encoding="cp1251") df.size >>172440
Problem description
The ‘c’ engine should read the files with non-UTF-8 filenames
Expected Output
File content readed into dataframe
Output of pd.show_versions()
INSTALLED VERSIONS
commit: None
python: 3.6.1.final.0
python-bits: 32
OS: Windows
OS-release: 7
machine: AMD64
processor: Intel64 Family 6 Model 42 Stepping 7, GenuineIntel
byteorder: little
LC_ALL: None
LANG: None
LOCALE: None.None
pandas: 0.20.3
pytest: None
pip: 9.0.1
setuptools: 28.8.0
Cython: None
numpy: 1.13.2
scipy: 0.19.1
xarray: None
IPython: 6.2.1
sphinx: None
patsy: None
dateutil: 2.6.1
pytz: 2017.2
blosc: None
bottleneck: None
tables: None
numexpr: None
feather: None
matplotlib: None
openpyxl: 2.4.8
xlrd: None
xlwt: None
xlsxwriter: None
lxml: 4.0.0
bs4: None
html5lib: 1.0b10
sqlalchemy: None
pymysql: None
psycopg2: None
jinja2: 2.9.6
s3fs: None
pandas_gbq: None
pandas_datareader: None
None
Один из самых популярных форматов данных является CSV. Для работы с CSV в Python есть несколько библиотек и модулей. С помощью их вы сможете обрабатывать эти данные конвертируя их в словари и списки, создавать файлы и читать их. Основной модуль называется CSV и большинство задач разберем на его примере.
Как устроен формат CSV
Основное отличие формата CSV от обычного текста в его структуре, которая проявляется в разделителе. Именно из-за этого этот формат расшифровывается как ‘comma separated values’ (значения разделенные запятыми). Разделитель не всегда обязан быть в виде запятой, он может принимать и другие виды, например ‘;’. Разделители так же могут называться делимитер (delimiter). Пример того, как может выглядеть файл:
Имя; Пол; Возраст Алексей; муж.; 20 Алина; жен.; 21Первая строка может содержать название заголовки колонок, но это не обязательно. Так же видно, что разделители разделяют значения и из-за этого они не используются в конце строки.
Из-за простого формата CSV вам не обязательно импортировать модули. Вы можете использовать существующий функционал, который создаст данные в формате CSV, например так:
data = [ ['Имя', 'Пол', 'Возраст'], ['Алексей', 'муж.', '20'], ['Алина', 'жен.', '21'], ] csv = '' for row in data: csv += ','.join(row) + 'n' 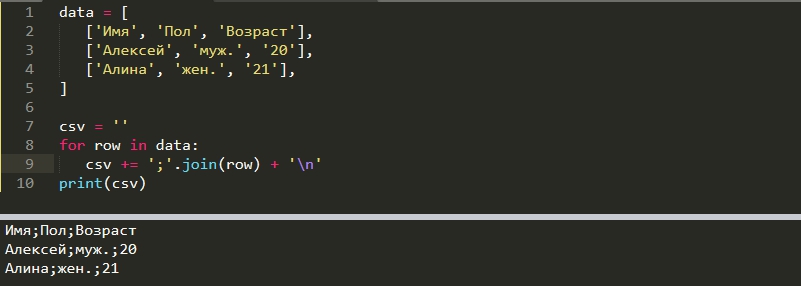
Тем не менее в модулях реализованы дополнительные возможности по анализу таких данных. Например преобразование в словарь или определение форматов (диалекта).
Чтение CSV файлов
Как уже говорилось, основной модуль уже установлен вместе с Python. Для чтения файлов используется функция ‘reader()’, которая возвращает объект для итерации. Так мы можем открыть файл в большинстве случаев:
import csv with open('file.csv', 'r') as f: data = csv.reader(f) for row in data: print(row)Для каких-то ОС может понадобится открывать файл с указанием разделителя новой строки, т.е. так:
with open('file.csv', 'r', newline='') as f:Указание разделителя
По умолчанию считается, что вы используете запятую в качестве делимитра. В моем файле, в качестве разделителя, стоит ‘;’, а файл содержит кириллицу (кириллица имеет значение на Windows). В этом случае файл читается следующим образом:
import csv with open('file.csv', 'r', encoding='UTF-8') as f: data = csv.reader(f, delimiter=';') for row in data: print(row)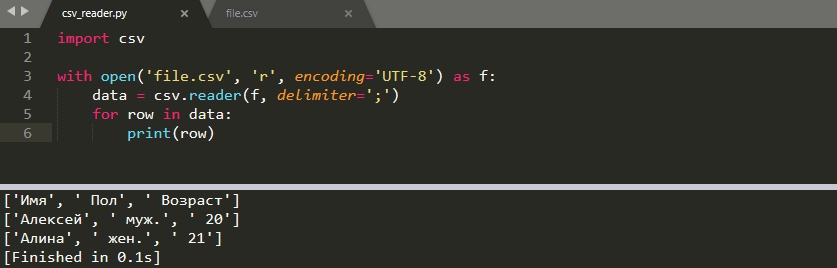
В случае Windows по умолчанию используется кодировка ‘cp1251’ и, если вы не укажете ‘UTF-8’, то может появится ошибка:
- UnicodeDecodeError: ‘charmap’ codec can’t decode byte 0x98 in position 1: character maps to
Начальные пробелы
Со скриншота выше видно, что пробелы, в начале строки, не обрабатываются должным образом. Что бы убрать пробелы нужно указать параметр ‘skipinitialspace’:
import csv with open('file.csv', 'r', encoding='UTF-8') as f: data = csv.reader(f, delimiter=';', skipinitialspace=True) for row in data: print(row)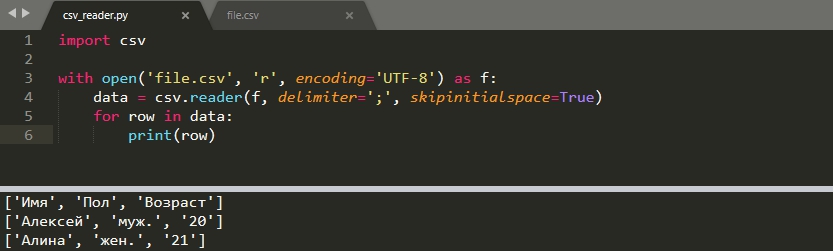
Кавычки
CSV файл может содержать кавычки в произвольных местах:
"Name","Age","Sex" "Alexander Melnikov",45,"m" "Piter Tolstoy",23,"m"Убрать их можно используя параметр ‘quoting’:
import csv with open('file.csv', 'r') as f: data = csv.reader(f, quoting=csv.QUOTE_ALL) for row in data: print(row)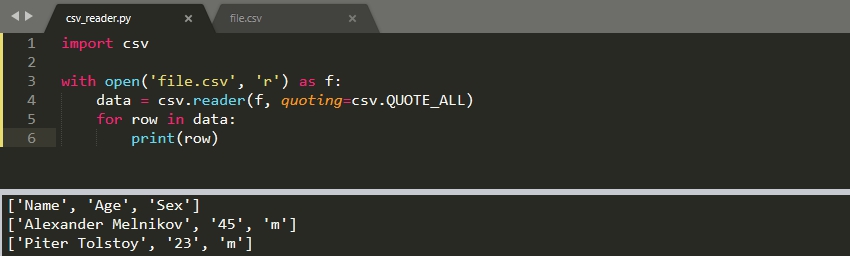
По умолчанию ищется двойная кавычка. Если вы хотите ее переопределить, то нужно использовать параметр ‘quotechar’.
Поиска этой кавычки зависит от того, что указано в параметр ‘quoting’. Так значение ‘csv.QUOTE_ALL‘ говорит, что все значения находятся внутри кавычек. Параметр может принимать другие значения:
- csv.QUOTE_MINIMAL — используется по умолчанию. Кавычки используются в местах содержащие специальные символы (например двойная кавычка из quotechar или сам дилиметр);
- csv.QUOTE_NONNUMERIC — кавычки используются в нечисловых значениях. Если кавычек в значении не присутствует оно будет преобразовано во float;
- csv.QUOTE_NONE — кавычки, вокруг значений, не используются.
Если вы установили ‘csv.QUOTE_NONE’, а в файле все равно экранируются специальные символы, то можно использовать параметр ‘escapechar’ указывающий на символ экранирования.
Чтение с конвертацией в словарь
Если первая строка у вас содержит заголовки колонок, то вы ее можно преобразовать в ключи словаря. Что бы это сделать, вместо метода ‘reader()’ используется класс ‘DictReader()’:
import csv with open('file.csv', 'r') as f: data = csv.DictReader(f, delimiter=';') for row in data: print(row) 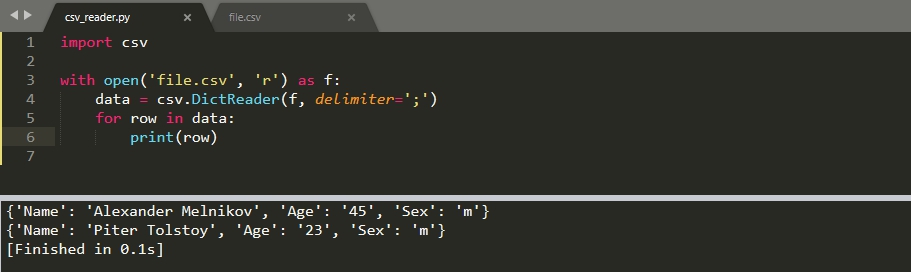
Тип словаря зависит от версии Python. Если вы используете версию ниже 3.8, то вернется ‘OrderedDict’, который можно преобразовать в обычный с ‘dict()’. В версиях 3.8 и старше возвращается обычный тип словаря.
Параметры у класса аналогичны методу ‘reader()’. Мы так же можем определять кавычки и символы экранирования.
Создание шаблона диалекта
Если у вас используется множество разных параметров и идет нарушение принципов DRY (dont repeat yorself), то вы можете использовать диалект (или просто шаблон). В примере мы регистрируем параметры под общим названием ‘myDialect’ и передаем в функцию или класс:
import csv csv.register_dialect('myDialect', delimiter=';', skipinitialspace=True, quoting=csv.QUOTE_ALL) with open('file1.csv', 'r') as f: data = csv.reader(f, dialect='myDialect') for row in data: print(row) with open('file2.csv', 'r') as f: data = csv.reader(f, dialect='myDialect') for row in data: print(row)Автоматическое определение параметров CSV файла
Если используются разные файлы CSV и в каждом из них разные параметры для чтения, мы можем определить их автоматически с классом ‘Sniffer’. Результат работы этого класса мы можем передать как диалект:
import csv with open('file.csv', 'r') as f: # читаем первые 100 символов (или весь файл) sample = f.read(100) # пример проверки, что файл имеет заголовки header = csv.Sniffer().has_header(sample) print('В файле есть заголовки: ', header) # создаем диалект dialect = csv.Sniffer().sniff(sample) with open('file.csv', 'r') as f: # передаем диалект и читаем файл reader = csv.reader(f, dialect) for row in reader: print(row)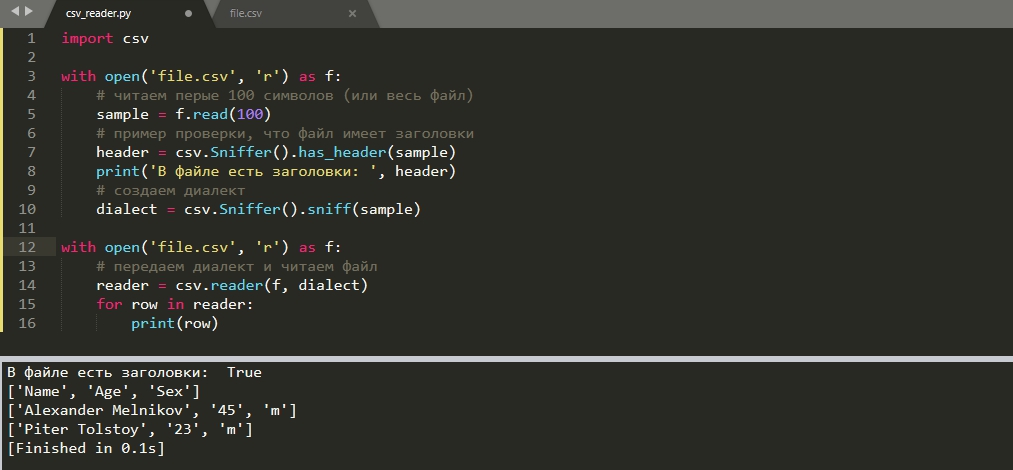
Метод ‘has_header()’ проверяет есть ли в файле заголовки. Аналогично этому методу могут быть использованы и другие методы проверяющие кавычки, делимитры и т.д.
Чтение в pandas
В библиотеке для анализа данных pandas так же есть возможность прочитать CSV файл. Эта библиотека устанавливается отдельно:
import pandas csv = pandas.read_csv('file.csv', delimiter=';') print(csv)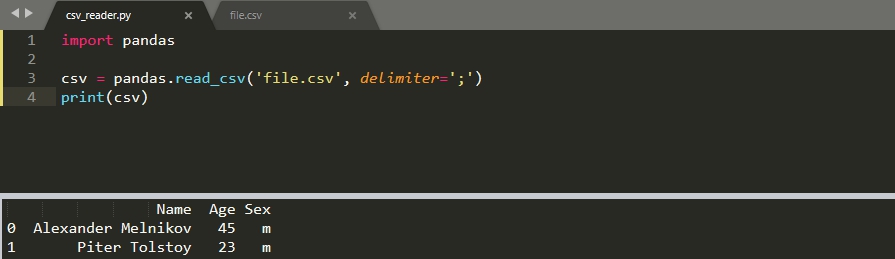
Запись данных в CSV
Для записи данных есть функция ‘writer()’. В эту функцию мы можем передать все те же параметры, что в случае чтения. Базовая запись данных будет выглядеть следующим образом:
import csv lines = [ ['Alexander Melnikov', '31', 'm'], ['Mihail Tolstoy', '28', 'm'], ] with open('file_w.csv', 'w', newline='') as f: writer = csv.writer(f) for line in lines: writer.writerow(line) # или просто # writer.writerows(lines)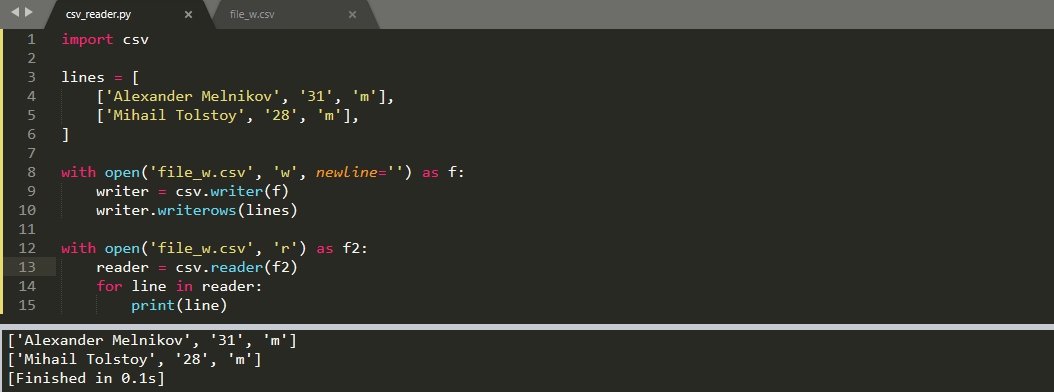
Как и понятно с примера выше:
- writerow — записывает каждый список построчно;
- writerows — записывает список списков в файл целиком.
Надобность в ‘newline’ так же может отличаться в разных ОС. Вы можете указать в функции ‘writer’ параметр ‘lineterminator’ со значением ‘n’, который обозначает символ переноса новой строки. По умолчанию он равен ‘rn’:
. with open('file_w.csv', 'w') as f: writer = csv.writer(f, lineterminator='n') . Аналогично ‘lineterminator’ могут передаваться следующие параметры:
- quotechar — символ для экранирования значений попадающие под условия указанные в ‘quoting’. По умолчанию этот символ равен двойным кавычкам;
- quoting — какие значения должны быть экранированы: csv.QUOTE_MINIMAL (если в значении есть делимитер или сам символ экранирования), csv.QUOTE_ALL (все символы), csv.QUOTE_NONNUMERIC (оборачивает в кавычки все нечисловые значения), csv.QUOTE_NONE (не использует кавычки и, если в значениях используется символ делимитера, экранирует его в ‘escapechar’);
- escapechar — если поведение с кавычками не установлено, то символы разделителя в значениях экранируются в этот символ.
import csv lines = [ ['Alexander, Melnikov', '31', 'm'], ['Mihail Tolstoy', '28', 'm'], ] with open('file_w.csv', 'w', newline='') as f: writer = csv.writer(f, escapechar='*', quoting=csv.QUOTE_NONE) writer.writerows(lines)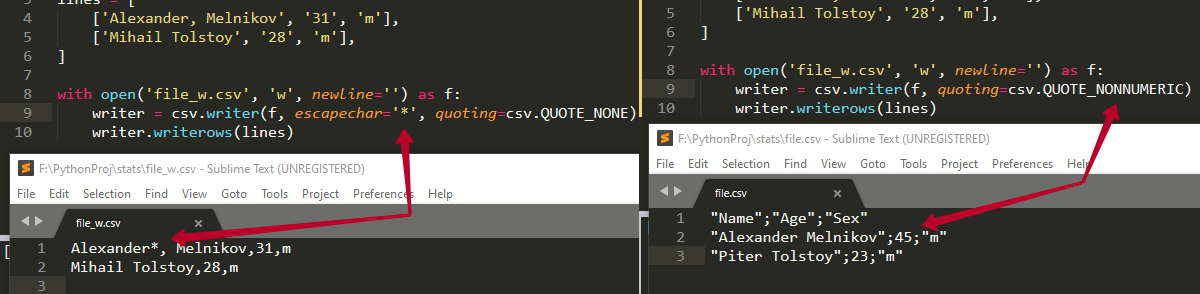
Запись словаря
Аналогично чтению мы можем выполнить конвертацию словаря в CSV. Для этого есть класс ‘DictWriter’. Запись словаря, от его чтения, отличается параметром ‘fieldnames’ в котором указываются заголовки колонок. Пример такой записи:
import csv lines = [ , , ] with open('file_w.csv', 'w', newline='') as f: writer = csv.DictWriter(f, fieldnames=['age','sex','name']) for line in lines: writer.writerow(line) # или просто # writer.writerows(lines)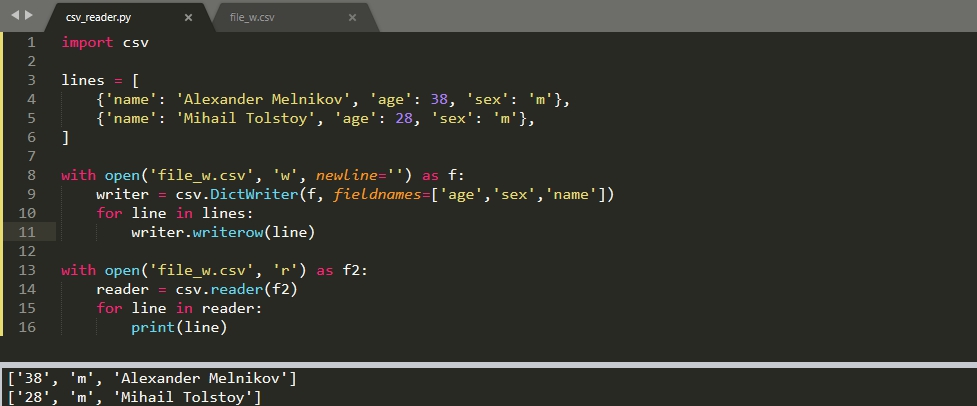
Параметры, переданные в ‘DictWriter’, могут быть такими же что и в ‘writer’.
Запись с pandas
Что бы сохранить данные с pandas мы сначала должны выполнить конвертацию в ‘DataFrame’:
import pandas as pd # словарь lines1 = [ , , ] # список lines2 = [ ['Alexander Melnikov', 38, 'm'], ['Mihail Tolstoy', 28, 'm'], ] lines1 = pd.DataFrame(lines1) lines2 = pd.DataFrame(lines2) lines1.to_csv('example1.csv') lines2.to_csv('example2.csv')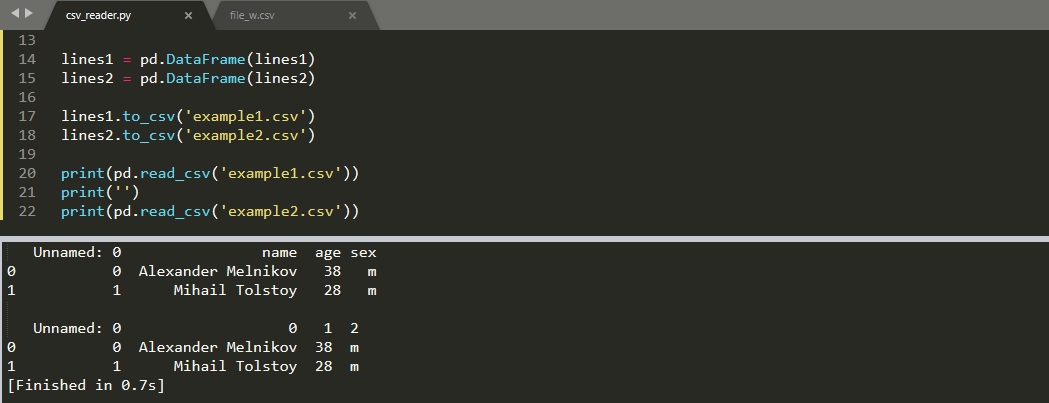
Кодировка в csv-файле
Помощь в написании контрольных, курсовых и дипломных работ здесь.
CSV Кодировка (Python3)
import requests from bs4 import BeautifulSoup import csv def get_html(url): r =.
Фильтрация строк в csv файле
Прошу помощи в реализации нужно удалить строки из csv содержащие определенные слова пробовал при.
Среднее значение столбца в csv файле
всем привет, пожалуйста помогите с этой задачей. не могу понять эти задачи csv. Дано: Загрузите.
Слетела кодировка в файле
Писал диплом, залагал комп, перегрузил винду открываю основную копию файла слетела кодировка.
| output.zip (511 байт, 6 просмотров) |
Решение
Добавлено через 7 минут
C трех попыток угадал 🙂
Неверное кодирование windows-1251 в windows-1252.
Админ написал, про кодировку: в полях varchar кодировка cp1251
А как правильно перекодировать? что то не получается.
Добавлено через 23 минуты
Ошибка:
UnicodeDecodeError: ‘charmap’ codec can’t decode byte 0x90 in position 63: character maps to
Добавлено через 6 минут
Ну если файл был записан на диск в неверной кодировке, значит его сначала нужно исправить и только потом пользоваться.
Добавлено через 2 минуты
Перекодировать файл можно и в обычном текстовом редакторе, только нужно понимать разницу между перекодировать файл и переоткрытьперечитать в другой кодировке и не перепутать последовательность этих операций: сначала перекодировать, затем перечитать
Я в двух текстовых редакторах легко это сделал: в Akelpad и SynWrite.
Вот я в этом пока не очень, если можете подсказать как это сделать буду признателен, сто то не получается, с оракла получилось исправить кодировку а тут нет((
Добавлено через 1 час 23 минуты
Пока не нашел ничего лучше, чем перекодировать каждый столбец:
Я же вам показал как за одну операцию перекодировать сразу весь файл.
Как его сразу создать с вменяемой кодировкой я не могу сказать, ничего не зная о том в какой кодировке выгружаются у вас данные из БД.
Добавлено через 9 минут
P.S. Можете попробовать сохранить файл в windows-1251:
Админам на заметку:
Чой-та за фигня творится c сохранением постов?
Добавлено через 11 минут
Ну и заодно попросить показать, что выдает команда: SHOW VARIABLES LIKE ‘character%’;
Импорт в csv и кодировка
Здаравствуйте. Создаю скриптом csv файл в кодировке UTF-8. Данные содержат символы.

Кодировка CSV файла
Доброго времени суток! Образовалась такая проблема: при создании сайта на php (задание такое.
Русская кодировка в текстовом csv
пытаюсь выводить текстовые данные в файл, но они же из обычных textbox и если их потом открыть как.
type of encoding to read csv files in pandas
2 Answers 2
Or iterate over several formats in a try/except statement:
A CSV file is a text file. If it contains only ASCII characters, no problem nowadays, most encodings can correctly handle plain ASCII characters. The problem arises with non ASCII characters. Exemple
| character | Latin1 code | cp850 code | UTF-8 codes |
|---|---|---|---|
| é | ‘xe9’ | ‘x82’ | ‘xc3xa9’ |
| è | ‘xe8’ | ‘x8a’ | ‘xc3xa8’ |
| ö | ‘xf6’ | ‘x94’ | ‘xc3xb6’ |
As you spoke of CP1252, it is a Windows variant of Latin1, but it does not share the property of being able to decode any byte.
The common way is to ask people sending you CSV file to use the same encoding and try to decode with that encoding. Then you have two workarounds for badly encoded files. First is the one proposed by CygnusX: try a sequence of encodings terminated with Latin1, for example encodings = [«utf-8-sig», «utf-8», «cp1252», «latin1»] (BTW Latin1 is an alias for ISO-8859-1 so no need to test both).
The second one is to open the file with errors=’replace’ : any offending byte will be replaced with a replacement character. At least all ASCII characters will be correct:
UnicodeDecodeError when reading CSV file in Pandas with Python
I’m running a program which is processing 30,000 similar files. A random number of them are stopping and producing this error.
The source/creation of these files all come from the same place. What’s the best way to correct this to proceed with the import?

23 Answers 23
You can also use one of several alias options like ‘latin’ instead of ‘ISO-8859-1’ (see python docs, also for numerous other encodings you may encounter).
Simplest of all Solutions:
Then, you can read your file as usual:
and the other different encoding types are:

Pandas allows to specify encoding, but does not allow to ignore errors not to automatically replace the offending bytes. So there is no one size fits all method but different ways depending on the actual use case.
You know the encoding, and there is no encoding error in the file. Great: you have just to specify the encoding:
You do not want to be bothered with encoding questions, and only want that damn file to load, no matter if some text fields contain garbage. Ok, you only have to use Latin1 encoding because it accept any possible byte as input (and convert it to the unicode character of same code):
You know that most of the file is written with a specific encoding, but it also contains encoding errors. A real world example is an UTF8 file that has been edited with a non utf8 editor and which contains some lines with a different encoding. Pandas has no provision for a special error processing, but Python open function has (assuming Python3), and read_csv accepts a file like object. Typical errors parameter to use here are ‘ignore’ which just suppresses the offending bytes or (IMHO better) ‘backslashreplace’ which replaces the offending bytes by their Python’s backslashed escape sequence:

after executing this code you will find encoding of ‘filename.csv’ then execute code as following

This is a more general script approach for the stated question.
One starts with all the standard encodings available for the python version (in this case 3.7 python 3.7 standard encodings). A usable python list of the standard encodings for the different python version is provided here: Helpful Stack overflow answer
Trying each encoding on a small chunk of the data; only printing the working encoding. The output is directly obvious. This output also addresses the problem that an encoding like ‘latin1’ that runs through with ought any error, does not necessarily produce the wanted outcome.
In case of the question, I would try this approach specific for problematic CSV file and then maybe try to use the found working encoding for all others.
In my case, a file has USC-2 LE BOM encoding, according to Notepad++. It is encoding=»utf_16_le» for python.
Hope, it helps to find an answer a bit faster for someone.

Try changing the encoding. In my case, encoding = «utf-16» worked.

Try specifying the engine=’python’. It worked for me but I’m still trying to figure out why.
In my case this worked for python 2.7:
And for python 3, only:
This will help. Worked for me. Also, make sure you’re using the correct delimiter and column names.
You can start with loading just 1000 rows to load the file quickly.

Struggled with this a while and thought I’d post on this question as it’s the first search result. Adding the encoding=»iso-8859-1″ tag to pandas read_csv didn’t work, nor did any other encoding, kept giving a UnicodeDecodeError.

Fortunately, there are a few solutions.
Option 1, fix the exporting. Be sure to use UTF-8 encoding.
Option 3: solution is my preferred solution personally. Read the file using vanilla Python.
Hope this helps people encountering this issue for the first time.
Pandas read_csv() tricks you should know to speed up your data analysis
Some of the most helpful Pandas tricks to speed up your data analysis

Aug 21, 2020 · 7 min read

Importing data is the first step in any data science project. Often, you’ll work with data in CSV files and run into problems at the very beginning. In this article, you’ll see how to use the Pandas read_csv() function to deal with the following common problems.
Please check out my Github repo for the source code.
1. Dealing with different character encodings
Character encodings are specific sets of rules for mapping from raw binary byte strings to characters that make up the human-readable text [1]. Python has built-in support for a list of standard encodings.
Character e n coding mismatches are less common today as UTF-8 is the standard text encoding in most of the programming languages including Python. However, it is definitely still a problem if you are trying to read a file with a different encoding than the one it was originally written. You are most likely to end up with something like below or DecodeError when that happens:
The Pandas read_csv() function has an argument call encoding that allows you to specify an encoding to use when reading a file.
Let’s take a look at an example below:
Then, you should get an UnicodeDecodeError when trying to read the file with the default utf8 encoding.

In order to read it correctly, you should pass the encoding that the file was written.

Headers refer to the column names. For some datasets, the headers may be completely missing, or you might want to consider a different row as headers. The read_csv() function has an argument called header that allows you to specify the headers to use.
If your CSV file does not have headers, then you need to set the argument header to None and the Pandas will generate some integer values as headers
For example to import data_2_no_headers.csv

Let’s take a look at data_2.csv
3. Dealing with columns
When your input dataset contains a large number of columns, and you want to load a subset of those columns into a DataFrame, then usecols will be very useful.
Performance-wise, it is better because instead of loading an entire DataFrame into memory and then deleting the spare columns, we can select the columns we need while loading the dataset.
Let’s use the same dataset data_2.csv and select the product and cost columns.

We can also pass the column index to usecols :
4. Parsing date columns
Date columns are represented as objects by default when loading data from a CSV file.
To read the date column correctly, we can use the argument parse_dates to specify a list of date columns.
To specify a custom column name instead of the auto-generated year_month_day, we can pass a dictionary instead.
If your date column is in a different format, then you can customize a date parser and pass it to the argument date_parser :
For more about parsing date columns, please check out this article
UnicodeDecodeError при чтении CSV-файла в панд с Python
Я запускаю программу, которая обрабатывает 30 000 подобных файлов. Случайное число из них останавливаются и производят эту ошибку.
источник / создание этих файлов все приходят из одного и того же места. Каков наилучший способ исправить это, чтобы продолжить импорт?
4 ответов:
самое простое из всех решений:
затем вы можете прочитать файл как обычно:
редактировать 1:
Если есть много файлов, то вы можете пропустить возвышенный шаг.
просто прочитайте файл с помощью
и другие различные типы кодирования:
Pandas позволяет указать кодировку, но не позволяет игнорировать ошибки, чтобы автоматически не заменять нарушающие байты. Так что нет один размер подходит всем метод, но разными способами в зависимости от фактического использования.
вы знаете кодировку, и в файле нет ошибки кодирования. Отлично: вам нужно просто указать кодировку:
вы не хотите, чтобы вас беспокоили вопросы кодирования, и только хочу, чтобы этот проклятый файл загружался, независимо от того, содержат ли некоторые текстовые поля мусор. Хорошо, вы только должны использовать Latin1 кодировка, потому что она принимает любой возможный байт в качестве входного (и преобразует его в символ Юникода того же кода):
вы знаете, что большая часть файла записывается в определенной кодировке, но он также содержит ошибки кодирования. Примером реального мира является файл UTF8, который был отредактирован с помощью редактора, отличного от utf8, и который содержит некоторые строки с другая кодировка. Панды не имеет никакого положения для специальной обработки ошибок, но Python open функция имеет (предполагая Python3), и read_csv принимает файл как объект. Типичные ошибки параметр для использования здесь ‘ignore’ который просто подавляет оскорбительные байты или (ИМХО лучше) ‘backslashreplace’ который заменяет оскорбительные байты их Python с обратной косой чертой escape-последовательности:
боролся с этим некоторое время и думал, что я отправлю на этот вопрос, так как это первый результат поиска. Добавление тега encoding=’iso-8859-1″ в pandas read_csv не работало, как и любая другая кодировка, продолжало давать UnicodeDecodeError.

So we’ve all gotten that error, you download a CSV from the web or get emailed it from your manager, who wants analysis done ASAP, and you find a card in your Kanban labelled URGENT AFF,so you open up VSCode, import Pandas and then type the following: pd.read_csv(‘some_important_file.csv’) .
Now, instead of the actual import happening, you get the following, near un-interpretable stacktrace:

What does that even mean?! And what the heck is utf-8 . As a brief primer/crash course, your computer (like all computers), stores everything as bits (or series of ones and zeros). Now, in order to represent human-readable things (think letters) from ones and zeros, the Internet Assigned Numbers Authority came together and came up with the ASCII mappings. These basically map bytes (binary bits) to codes (in base-10, so numbers) which represent various characters. For example, 00111111 is the binary for 063 which is the code for ? .
These letters then come together to form words which form sentences. The number of unique characters that ASCII can handle is limited by the number of unique bytes (combinations of 1 and 0 ) available. However, to summarize: using 8 bits allows for 256 unique characters which is NO where close in handling every single character from every single language. This is where Unicode comes in; unicode assigns a «code points» in hexadecimal to each character. For example U+1F602 maps to 😂. This way, there are potentially millions of combinations, and is far broader than the original ASCII.
UTF-8 translates Unicode characters to a unique binary string, and vice versa. However, UTF-8, as its name suggests, uses an 8-bit word (similar to ASCII), to save memory. This is similar to a technique known as Huffman Coding which represents the most-used characters or tokens as the shortest words. This is intuitive in the sense that, we can afford to assign tokens used the least to larger bytes, as they are less likely to be sent together. If every character would be sent in 4 bytes instead, every text file you have would take up four times the space.
However, this also means that the number of characters encoded by specifically UTF-8, is limited (just like ASCII). There are other UTFs (such as 16), however, this raises a key limitation, especially in the field of data science: sometimes we either don’t need the non-UTF characters or can’t process them, or we need to save on space. Therefore, here are three ways I handle non-UTF-8 characters for reading into a Pandas dataframe:
Find the correct Encoding Using Python
Pandas, by default, assumes utf-8 encoding every time you do pandas.read_csv , and it can feel like staring into a crystal ball trying to figure out the correct encoding. Your first bet is to use vanilla Python:
with open('file_name.csv') as f: print(f) Enter fullscreen mode
Exit fullscreen mode
Most of the time, the output resembles the following:
name='file_name.csv' mode='r' encoding='utf16'> Enter fullscreen mode
Exit fullscreen mode
.
If that fails, we can move onto the second option
Find Using Python Chardet
chardet is a library for decoding characters, once installed you can use the following to determine encoding:
import chardet with open('file_name.csv') as f: chardet.detect(f) Enter fullscreen mode
Exit fullscreen mode
The output should resemble the following:
'encoding': 'EUC-JP', 'confidence': 0.99> Enter fullscreen mode
Exit fullscreen mode
The last option is using the Linux CLI (fine, I lied when I said three methods using Pandas)
iconv -f utf-8 -t utf-8 -c filepath -o CLEAN_FILE Enter fullscreen mode
Exit fullscreen mode
- The first utf-8 after f defined what we think the original file format is
- t is the target file format we wish to convert to (in this case utf-8 )
- c skips ivalid sequences
- o outputs the fixed file to an actual filepath (instead of the terminal)
Now that you have your encoding, you can go on to read your CSV file successfully by specifying it in your read_csv command such as here:
pd.read_csv("some_csv.txt", encoding="not utf-8") Enter fullscreen mode
Exit fullscreen mode
Кодировка в csv-файле
CSV Кодировка (Python3)
import requests from bs4 import BeautifulSoup import csv def get_html(url): r =.
Фильтрация строк в csv файле
Прошу помощи в реализации нужно удалить строки из csv содержащие определенные слова пробовал при.
Среднее значение столбца в csv файле
всем привет, пожалуйста помогите с этой задачей. не могу понять эти задачи csv. Дано: Загрузите.
Слетела кодировка в файле
Писал диплом, залагал комп, перегрузил винду открываю основную копию файла слетела кодировка.
| output.zip (511 байт, 6 просмотров) |
Решение
Ищешь в гугле таблицу кракозябр — пытаешься перекодировать.
Я посмотрел: результат похож на неверное кодирование из ISO-8859-5 в windows-12512.
Добавлено через 7 минут
C трех попыток угадал 🙂
Неверное кодирование windows-1251 в windows-1252.
Админ написал, про кодировку: в полях varchar кодировка cp1251
А как правильно перекодировать? что то не получается.
Добавлено через 23 минуты
Ошибка:
UnicodeDecodeError: ‘charmap’ codec can’t decode byte 0x90 in position 63: character maps to
Добавлено через 6 минут
Ну если файл был записан на диск в неверной кодировке, значит его сначала нужно исправить и только потом пользоваться.
Добавлено через 2 минуты
Перекодировать файл можно и в обычном текстовом редакторе, только нужно понимать разницу между перекодировать файл и переоткрытьперечитать в другой кодировке и не перепутать последовательность этих операций: сначала перекодировать, затем перечитать
Я в двух текстовых редакторах легко это сделал: в Akelpad и SynWrite.
Вот я в этом пока не очень, если можете подсказать как это сделать буду признателен, сто то не получается, с оракла получилось исправить кодировку а тут нет((
Добавлено через 1 час 23 минуты
Пока не нашел ничего лучше, чем перекодировать каждый столбец:
Я же вам показал как за одну операцию перекодировать сразу весь файл.
Как его сразу создать с вменяемой кодировкой я не могу сказать, ничего не зная о том в какой кодировке выгружаются у вас данные из БД.
to_csv сохраняет по умолчанию в utf-8, но на ее уровне ничего не изменишь — ваша проблема это сама БД, которая выдает вовсе не utf-8 и даже не windows-1251.
Добавлено через 9 минут
P.S. Можете попробовать сохранить файл в windows-1251:
Если не получится — пробуйте windows-1252.
Админам на заметку:
Чой-та за фигня творится c сохранением постов?
Тематические курсы и обучение профессиям онлайн
Профессия Python-разработчик (Skillbox)
Профессия Fullstack-разработчик на Python (Skillbox)
Python-разработчик с нуля (Нетология)
Fullstack-разработчик на Python (Нетология)
Сказать админу, чтобы он перевел все записи в UTF-8, а еще лучше — в utf8mb4.
Добавлено через 11 минут
Ну и заодно попросить показать, что выдает команда: SHOW VARIABLES LIKE ‘character%’;
Заказываю контрольные, курсовые, дипломные и любые другие студенческие работы здесь или здесь.
Кодировка файла csv
Здравствуйте, подскажите, пожалуйста. Таблица с расширением .csv импортируется на сайт сделанный на.
Импорт в csv и кодировка
Здаравствуйте. Создаю скриптом csv файл в кодировке UTF-8. Данные содержат символы.
Кодировка CSV файла
Доброго времени суток! Образовалась такая проблема: при создании сайта на php (задание такое.
Русская кодировка в текстовом csv
пытаюсь выводить текстовые данные в файл, но они же из обычных textbox и если их потом открыть как.
Экспорт их Exel в CSV — Кодировка
Есть Exel файл. Там есть русские символы и они отображаются нормально. Но если я экспортирую в csv.
Разбор csv файла — неверная кодировка
Разбираю csv файл var lines = File.ReadAllLines(path); foreach (var l in lines) .
Python-сообщество
Уведомления
#1 Июнь 6, 2016 12:26:17
CSV-файл — определение и изменение кодировки
В наличии CSV-файл с таблицей и разделителями точка с запятой, который содержит список фамилий на русском языке. Есть необходимость удалить из файла определённые строки, решил я это делать при помощи регулярных выражений. Однако возникла проблема.
Сырой вывод через print(repr()) выводит русские символы следующим образом:
“xc0xe1xe0xf8xe8xe4xe7xe5 xc0.xc0.;;;n”
Как результат регулярка не цепляет русские символы, так как видит эту абракадабру, насколько я понимаю.
Какие есть варианты для решения проблемы? Не совсем ясно в какой кодировке файл (pyCharm в нижнем правом углу выставил ISO-8859-1), его лучше перекодировать в какой-либо другой формат, в котором регулярка будет цеплять кириллицу, или же в питоне есть возможность настроить регулярки?
Отредактировано coffe4wolf (Июнь 6, 2016 12:27:16)
#2 Июнь 6, 2016 21:42:01
CSV-файл — определение и изменение кодировки
coffe4wolf
Однако возникла проблема. Сырой вывод через print(repr())
#3 Июнь 7, 2016 10:12:51
CSV-файл — определение и изменение кодировки
doza_and
doza_and
1. Проблема не в принте. Открывать файл надо с указанием его кодировки.
Но ведь у open нет атрибута encoding о.О
#4 Июнь 7, 2016 22:06:48
CSV-файл — определение и изменение кодировки
coffe4wolf
Но ведь у open нет атрибута encoding о.О
#5 Июнь 8, 2016 11:48:22
CSV-файл — определение и изменение кодировки
doza_and
О, таки благодарю, не знал. Использую версию 2.7
Попробовал этим методом, но пайчам выплюнул ошибки
Не пойму почему он ругается на режим чтения. При открытии с определением кодировки нужно считывать файл в другом режиме?
Отредактировано coffe4wolf (Июнь 8, 2016 11:51:28)
#6 Июнь 8, 2016 12:04:51
CSV-файл — определение и изменение кодировки
Вы бы уже сам файлик приложили кусочек?
Влодение рускай арфаграфией — это как владение кунг-фу: настаящие мастира не преминяют ево бес ниабхадимости
#7 Июнь 8, 2016 12:10:12
CSV-файл — определение и изменение кодировки
Тащемта вот мучаемый файл

Прикреплённый файлы:
testcsv.csv (45,8 KБ)
#8 Июнь 8, 2016 14:17:02
CSV-файл — определение и изменение кодировки
:: ФИОПервый приходПоследний уход,Boscolo L.,Munhos de Campos E.,Абашидзе А.А.,Абдураимова У.З.,Абрамов Д.А.,Абрамов Е.Н.,Абрамов
Влодение рускай арфаграфией — это как владение кунг-фу: настаящие мастира не преминяют ево бес ниабхадимости
#9 Июнь 8, 2016 17:16:48
CSV-файл — определение и изменение кодировки
ZerG
О, таки ништяк.
Однако у меня пайчам всё равно выводит фигню

Прикреплённый файлы:
вывод.jpg (54,3 KБ)
#10 Июнь 8, 2016 19:34:34
CSV-файл — определение и изменение кодировки
Ну так давайте разберемся? Какая у вас ос? Какая кодировка?
Покажите код? Шрифт опять же — далеко не все поддерживают русские. Попробуйте Consolas для консоли поставить и так далее?
Опять же настройки кодировки в пишарме?
Что если запустить скрипт из консоли?
Что если дописать 5 строк кода и полученные данные сохранить в текстовый файл а пото открыть его каким то редактором?
Вы видите как много “что если”?
Влодение рускай арфаграфией — это как владение кунг-фу: настаящие мастира не преминяют ево бес ниабхадимости
Отредактировано ZerG (Июнь 8, 2016 19:36:10)
Как прочитать файл в кодировке cp1251?
Как правильно вывести файл в кодировке UTF-16LE?
Друзья! НА самом-то деле я всё правильно делаю. Вот код: import codecs f = codecs.open.
Как прочитать файл?
Всем привет! Я новичок в Python. ————————————— Мне нужно что бы эта.
Считать файл, заменить текст, сохранить файл в новой кодировке
Доброго времени суток уважаемые! Никак не могу справиться с элементарной казалось бы задачей.
Запись в файл в нужной кодировке
Доброго дня! Получаю веб-страницу через сокет, отображаю в среде — html отлично читается.
У меня все нормально. Ты с консолью виндовой работаешь? Я просто пробовал в IDLE.
Если в консоли, то тебе нужно преобразовать в данные в кодировку cp688.
С консолью Pycharm. Ну он наверное виндовую использует.
Добавлено через 3 минуты
С консолью Pycharm. Ну он наверное виндовую использует.
Добавлено через 3 минуты
спасибо, что поправил
ошибся
Добавлено через 3 минуты
DarthLenin, попробуй ещё раз с учётом изменившейся информации
кодировка — это именованный аргумент
всё правильно выдаёт, там ожидается тип буферизации
Тематические курсы и обучение профессиям онлайн
Профессия Python-разработчик (Skillbox)
Профессия Fullstack-разработчик на Python (Skillbox)
Python-разработчик с нуля (Нетология)
Fullstack-разработчик на Python (Нетология)
Заказываю контрольные, курсовые, дипломные и любые другие студенческие работы здесь или здесь.
Прочитать файл в кодировке cp1251 и перевести в кодировки koi8r, iso88595, unicode, microsoft sp866
работа с кодовыми таблицами русского языка дан исходный текст , кодировка cp-1251 составить.
Как прочитать файл в DOS-кодировке ?
У меня есть файл в DOS-кодировке. Как мне считать оттуда строку, чтобы она нормально отображалась.
Как можно прочитать файл текстовый в кодировке UTF-8?
Как можно прочитать файл текстовый в кодировке UTF-8?(при чтении c помощью FileSystemObject вместо.
Как прочитать текстовый файл в кодировке Win1251 (VS2005)?
Проект: textbox и две кнопки для вывода текста в разных кодировках. Вывожу текст в textbox1 Unicod.
Python-сообщество
Уведомления
#1 Июнь 6, 2016 12:26:17
CSV-файл — определение и изменение кодировки
В наличии CSV-файл с таблицей и разделителями точка с запятой, который содержит список фамилий на русском языке. Есть необходимость удалить из файла определённые строки, решил я это делать при помощи регулярных выражений. Однако возникла проблема.
Сырой вывод через print(repr()) выводит русские символы следующим образом:
“xc0xe1xe0xf8xe8xe4xe7xe5 xc0.xc0.;;;n”
Как результат регулярка не цепляет русские символы, так как видит эту абракадабру, насколько я понимаю.
Какие есть варианты для решения проблемы? Не совсем ясно в какой кодировке файл (pyCharm в нижнем правом углу выставил ISO-8859-1), его лучше перекодировать в какой-либо другой формат, в котором регулярка будет цеплять кириллицу, или же в питоне есть возможность настроить регулярки?
Отредактировано coffe4wolf (Июнь 6, 2016 12:27:16)
#2 Июнь 6, 2016 21:42:01
CSV-файл — определение и изменение кодировки
coffe4wolf
Однако возникла проблема. Сырой вывод через print(repr())
#3 Июнь 7, 2016 10:12:51
CSV-файл — определение и изменение кодировки
doza_and
doza_and
1. Проблема не в принте. Открывать файл надо с указанием его кодировки.
Но ведь у open нет атрибута encoding о.О
#4 Июнь 7, 2016 22:06:48
CSV-файл — определение и изменение кодировки
coffe4wolf
Но ведь у open нет атрибута encoding о.О
#5 Июнь 8, 2016 11:48:22
CSV-файл — определение и изменение кодировки
doza_and
О, таки благодарю, не знал. Использую версию 2.7
Попробовал этим методом, но пайчам выплюнул ошибки
Не пойму почему он ругается на режим чтения. При открытии с определением кодировки нужно считывать файл в другом режиме?
Отредактировано coffe4wolf (Июнь 8, 2016 11:51:28)
#6 Июнь 8, 2016 12:04:51
CSV-файл — определение и изменение кодировки
Вы бы уже сам файлик приложили кусочек?
Влодение рускай арфаграфией — это как владение кунг-фу: настаящие мастира не преминяют ево бес ниабхадимости
#7 Июнь 8, 2016 12:10:12
CSV-файл — определение и изменение кодировки
Тащемта вот мучаемый файл
Прикреплённый файлы:
testcsv.csv (45,8 KБ)
#8 Июнь 8, 2016 14:17:02
CSV-файл — определение и изменение кодировки
:: ФИОПервый приходПоследний уход,Boscolo L.,Munhos de Campos E.,Абашидзе А.А.,Абдураимова У.З.,Абрамов Д.А.,Абрамов Е.Н.,Абрамов
Влодение рускай арфаграфией — это как владение кунг-фу: настаящие мастира не преминяют ево бес ниабхадимости
#9 Июнь 8, 2016 17:16:48
CSV-файл — определение и изменение кодировки
ZerG
О, таки ништяк.
Однако у меня пайчам всё равно выводит фигню
Прикреплённый файлы:
вывод.jpg (54,3 KБ)
#10 Июнь 8, 2016 19:34:34
CSV-файл — определение и изменение кодировки
Ну так давайте разберемся? Какая у вас ос? Какая кодировка?
Покажите код? Шрифт опять же — далеко не все поддерживают русские. Попробуйте Consolas для консоли поставить и так далее?
Опять же настройки кодировки в пишарме?
Что если запустить скрипт из консоли?
Что если дописать 5 строк кода и полученные данные сохранить в текстовый файл а пото открыть его каким то редактором?
Вы видите как много “что если”?
Влодение рускай арфаграфией — это как владение кунг-фу: настаящие мастира не преминяют ево бес ниабхадимости
Отредактировано ZerG (Июнь 8, 2016 19:36:10)